How to automate YouTube videos tracking with Make
The purpose of this post and the video above is to demonstrate how to extract data from your/any YouTube channel whenever a video is published. We'll download the video's captions and upload them to a Google Doc in a specific Drive folder. We'll also track the video data in a spreadsheet, including details such as the title, description, content (captions), publish date, URL, and thumbnail.
This could be useful because once you extract this data automatically from YouTube, you can store it in a spreadsheet, CSV file, Google Docs, or PDF. This content can later be used to feed your own AI agent or chatbot. By embedding this bot on your website, users can interact with it, retrieving knowledge from your content. Or you can merely store the content for analytics purposes, further enriching it using the YouTube Analytics API.
While this post focuses on YouTube, this process could also be applied to other platforms, like websites or blogs. Once we extract this data, we can manipulate it and feed it into an AI Vector database to make it accessible for chatbots.
In this post, we're focusing on the extraction part: how to extract videos and captions from YouTube and store that data in a dedicated spreadsheet and documents. We'll be using Make, which recently released native YouTube modules. This includes searching for videos, watching videos in a specific playlist, and uploading videos.
For our use case, we'll use the "watch videos in a channel" module to retrieve new videos whenever they're published. We'll also use the YouTube API (custom HTTP Oauth 2.0 calls) to get the captions, download them, and upload them to Google Drive. We'll also store the video data in a Google Sheet.
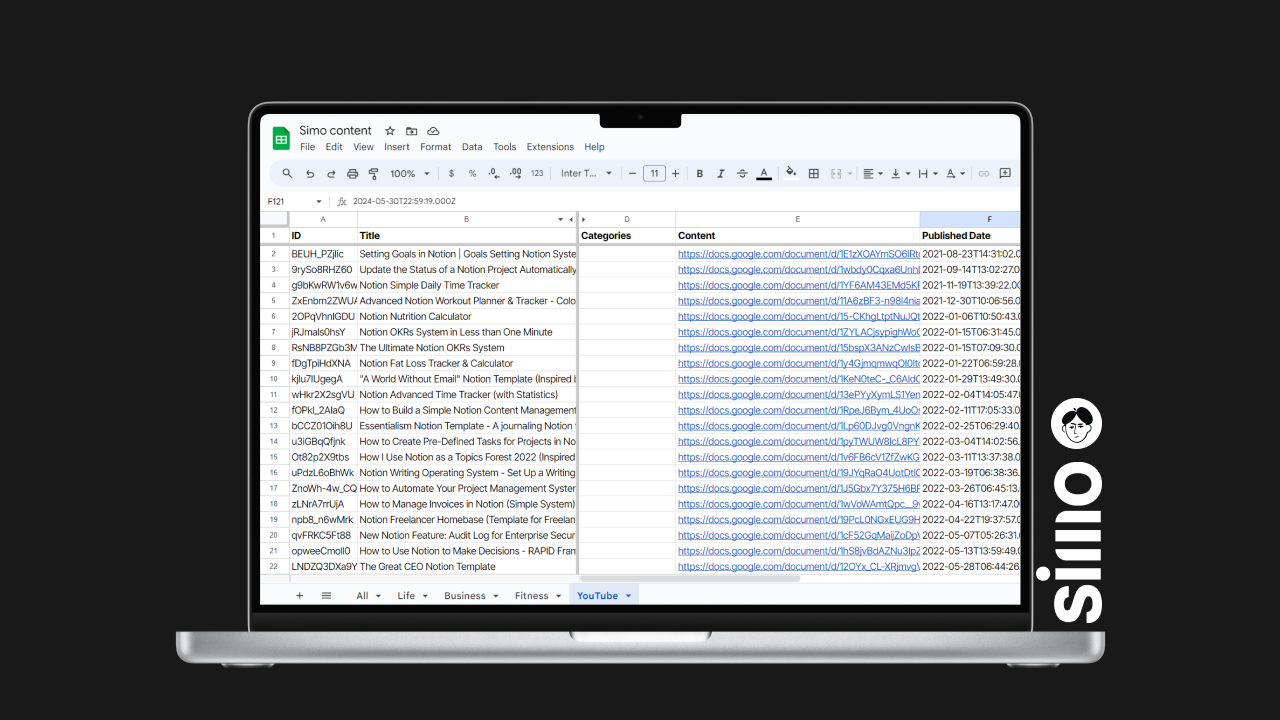
This entire process results in a spreadsheet with all the videos' details, descriptions, and Google Docs containing the captions. This written content can be fed into a large language model to query knowledge when a user or I interact with it.
Now, let's look at the details of the Make scenario and how I built it. First, there is the "watch videos in a channel" module. Here, I established a connection and inserted my channel ID. You can insert any channel ID you want here. Then I set a limit on how many videos the API should return when it runs.
Next, I used the YouTube API via Oauth 2.0 HTTP calls (because there is no native endpoint for that) to get the captions, using the video ID from the previous module. Once we have the captions, we upload them to Google Drive using the "upload a file" module. These files are then converted to Google Docs.
Lastly, we add the content to a Google Sheet, mapping all the values for each column from the previous modules. This includes details like the video ID, title, publish date, URL, script date, and thumbnail image.
The end result is a master Google Sheet tab where all the content is added every week. You can also use Notion/Coda/Airtable, or other database apps as a destination for storing the YouTube content data.